The information given below is taken from bgpexpert.com. Please thanks to them if you find these information useful..

|
|

|
Table of contents (for this page):
BGP and IPv6 routing coursesSeveral times a year I teach two training courses, one about BGP and one about IPv6. The BGP course is half theory and half hands-on practice, and so is the new IPv6 routing course. Previously, we did an IPv6 course without a hands-on part. The courses consists of a theory part in the morning and a practical part in the afternoon where the participants implement several assignments on a Cisco router (in groups of two participants per router).The next dates are October 6 for the BGP course in English and October 7 for the IPv6 routing course in English. (There will be dates for the courses in Dutch later in 2014 or early 2015.) Go to the NL-ix website to find more information and sign up. The location will be The Hague, Netherlands. Interdomain Routing & IPv6 News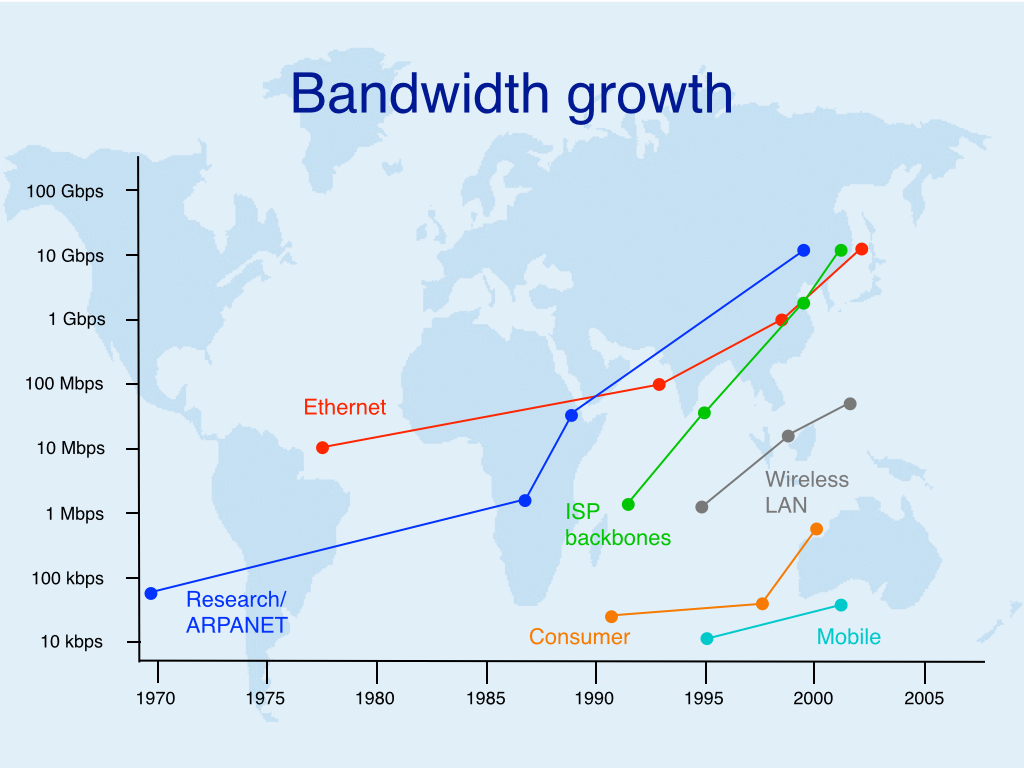 So I wondered what happened in the intermediate decade. Which would be: 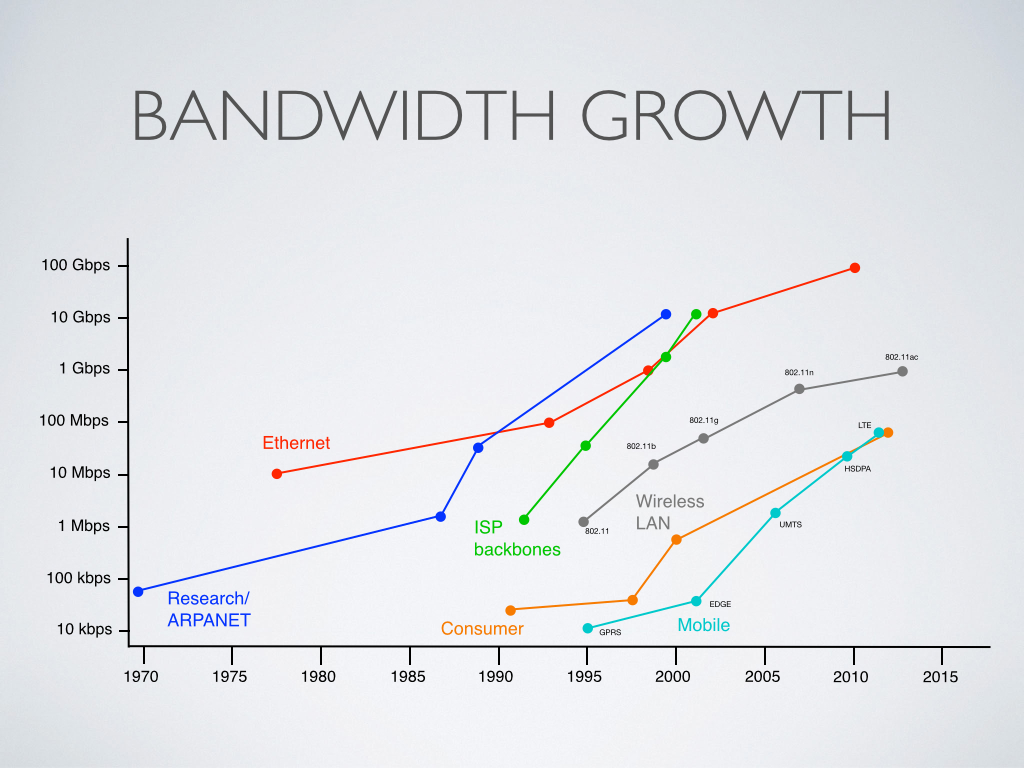 My impression that Ethernet had run out of steam is not entirely correct, the progression to 100 Gbps is roughly in line with the earlier growth path. Wi-Fi looks a little less impressive than I had thought on this logarithmic scale. However, there's just one super star here: mobile. It's hard to believe that we went from 100 kbps or so EDGE to 100 Mbps LTE in about a decade. Not everyone may be using LTE just yet, but 14 Mbps UMTS HSPA is in very wide use, there is really no reason to use anything less. Read the whole article So what's a FIB and why would it be limited to 512k (524288) prefixes?BGP routers actually have (at least) three different tables where IP address prefixes are stored, along with a next hop address: the BGP RIB, the main routing table / RIB and the FIB. The BGP Routing Information Base collects all information received over BGP that's not immediately filtered out. So if you have two ISPs, they will both send all the prefixes for all networks in the world that are currently reachable—which means that your router has two copies of every prefix, one with a next hop address pointing to ISP A and one with a next hop pointing to ISP B.For each prefix, BGP then decides which path is better and sends the prefix plus next hop address pointing to either A or B to the main routing table. The main routing table also holds non-BGP routing information. In large networks, all the internal stuff and routes for customers can add up to thousands or tens of thousands of routing table entries. Finally, a Forwarding Information Base (FIB) is constructed from the main routing table that is used to actually forward packets to the router identified by the next hop address. Some routers use regular RAM to store the FIB, others use a Ternary Content Addressable Memory. RAM sizes are pretty large these days and typically don't have a fixed limit, as it's shared by many processes running on a router. But TCAMs are special memories with a tiny bit of processing power. Basically, you can show a prefix to a TCAM and then the TCAM will tell you the address where that prefix is stored—you don't have to search through the memory one step at a time. This means TCAMs are very fast, but they are also more expensive than RAM and they run fairly hot. So TCAM sizes are limited. Nothing new under the sunCisco 6500 and 7600 modular routers/switches used to have supervisor modules with a TCAM limit of 256k. And then in 2008 the routing table grew to 256k, so people had to upgrade in a hurry. If they bought new supervisor modules that can handle 512k, they got six years of use out of those, hence Geoff Huston's statement that "Nothing in BGP looks like it's melting".Because different networks have different numbers of internal prefixes and there are also slight differences between the number of prefixes each ISP announces to its customers, different people get bitten by the issue at different times. Also, TCAMs are often partitioned into different parts: one for the IPv4 routing table, one for the IPv6 routing table, one for MPLS, one for filtering... In some cases, simply changing the partitioning is enough to get by for a while. Alternatively, it's always possible to filter BGP prefixes. As Randy Bush says: ❝half the routing table is deagg crap. filter it.❞The trouble is, you then lose connectivity towards the filtered prefixes, and there is no obvious way to only filter out the prefixes that are unnecessary deaggregation. If your network is non-huge, the solution is to use a default route pointing to your ISP / one of your ISPs as a safety net. What I used to do many years ago when using severely underpowered routers to run BGP is simply filter out all AS paths longer than five ASes from both our ISPs. Then, if one ISP has a long path and one a short path, I'd still have the short path which I'd want to use anyway. If neither had a short path, chances were it was a non-critical prefix far away, so handling it through a possibly non-optimal default route was unlikely to be problematic. However, large networks don't have anyone they can point a default route to. So they have to have more recent routers, and they pretty much always do. However, it's not unheard of for older network equipment live out its final years in far away corners of big networks, so they could still have minor issues. Mea culpaAlthough during my training courses, I always warn people that they should buy routers big enough to hold enough prefixes for some years to come, I really should have been more explicit and posted a warning here on this site. At least Cisco did: The Size of the Internet Global Routing Table and Its Potential Side Effects.The futureGeoff Huston expects the IPv4 table to hit 1 million in 2019 and recommends buying routers that can handle at least 2 million prefixes. Unfortunately, it's not always obvious how many prefixes a router can handle, especially if the TCAM is used for more than just the IPv4 FIB. So make sure what the limits are before you spend your money. Also, keep an eye on the weekly routing table report so you can take action when the BGP table starts creeping up to your routers' limits.Further reading:
When we added an IPv6 training course, the content was based on my IPv6 book, which didn't really lend itself to the same approach because it covers a much wider range of topics: enabling IPv6 on various operating systems, routing, tunnels, DNS, applications, security. I was never really happy doing just theory with no hands-on part. So I decided to focus more on routing with the IPv6 training course, and include tunnel, OSPF, BGP and DHCPv6 assignments so the participants can get some hands-on experience with the new protocol. As always, there were a few surprises when participants were trying to do the assignments for the first time, but the new format was a success. If you're interested in one of these training courses (or both), the next dates are October 6 for the BGP course and October 7 for the IPv6 routing course. The location is the NL-ix office in The Hague, and the language will be English unless all participants speak Dutch. (The next time after October the language will be Dutch.) See the NL-ix training course page for details and the sign up form. Archives of all articles - RSS feed My Books: "BGP" and "Running IPv6"On this page you can find more information about my book "BGP". Or you can jump immediately to chapter 6, "Traffic Engineering", (approx. 150kB) that O'Reilly has put online as a sample chapter. Information about the Japanese translation can be found here. More information about my second book, "Running IPv6", is available here. Apress, my new publisher, also has a sample chapter available: Chapter 5, The DNS."no synchronization"When you run BGP on two or more routers, you need to configure internal BGP (iBGP) between all of them. If those routers are Cisco routers, they won't work very well unless you configure them with no synchronization. The no synchronization configuration command tells the routers that you don't want them to "synchronize" iBGP and the internal routing protocol such as OSPF. The idea behind synchronizing is that when you have two iBGP speaking routers with another router in between that doesn't speak BGP, the non-BGP router in the middle needs to have the same routing information as the BGP routers, or there could be routing loops. The way to make sure that the non-BGP router is aware of the routing information in BGP, is to redistribute the BGP routing information into the internal routing protocol.By default, Cisco routers expect you to do this, and wait for the BGP routing information to show up in an internal routing protocol before they'll use any routes learned through iBGP. However, these days redistributing full BGP routing into another protocol isn't really done any more, because it's easier to simply run BGP on any routers in the middle. But if you don't redistribute BGP into internal routing, the router will still wait for the BGP routes to show up in an internal routing protocol, which will never happen, so the iBGP routes are never used. The "no synchronization" configuration command tells the routers they shouldn't wait for this synchronization, but just go ahead and use the iBGP routes. BGP SecurityBGP has some security holes. This sounds very bad, and of course it isn't good, but don't be overly alarmed. There are basically two problems: sessions can be hijacked, and it is possible to inject incorrect information into the BGP tables for someone who can either hijack a session or someone who has a legitimate BGP session. Session hijacking is hard to do for someone who can't see the TCP sequence number for the TCP session the BGP protocol runs over, and if there are good anti-spoofing filters it is even impossible. And of course using the TCP MD5 password option (RFC 2385) makes all of this nearly impossible even for someone who can sniff the BGP traffic.Nearly all ISPs filter BGP information from customers, so in most cases it isn't possible to successfully inject false information. However, filtering on peering sessions between ISPs isn't as widespread, although some networks do this. A rogue ISP could do some real damage here. There are now two efforts underway to better secure BGP:
IPv6BGPexpert is available over IPv6 as well as IPv4. www.bgpexpert.com has both an IPv4 and an IPv6 address. You can see which one you're connected to at the bottom of the page. Alternatively, you can click on www.ipv6.bgpexpert.com to see if you can connect over IPv6. This URL only has an IPv6 address.What is BGPexpert.com?BGPexpert.com is a website dedicated to Internet routing issues. What we want is for packets to find their way from one end of the globe to another, and make the jobs of the people that make this happen a little easier. Your host is Iljitsch van Beijnum. Feedback, comments, link requests... everything is welcome. You can read more about me here or email me at iljitsch@bgpexpert. or follow iljitsch on Twitter.Ok, but what is BGP?Have a look at the "what is BGP" page. There is also a list of BGP and interdomain routing terms on this page.BGP and MultihomingIf you are not an ISP, your main reason to be interested in BGP will probably be to multihome. By connecting to two or more ISPs at the same time, you are "multihomed" and you no longer have to depend on a single ISP for your network connectivity. This sounds simple enough, but as always, there is a catch. For regular customers, it's the Internet Service Provider who makes sure the rest of the Internet knows where packets have to be sent to reach their customer. If you are multihomed, you can't let your ISP do this, because then you would have to depend on a single ISP again. This is where the BGP protocol comes in: this is the protocol used to carry this information from ISP to ISP. By announcing reachability information for your network to two ISPs, you can make sure everybody still knows how to reach you if one of those ISPs has an outage.Want to know more? Read A Look at Multihoming and BGP, an article about multihoming I wrote for the O'Reilly Network. For those of you interested in multihoming in IPv6 (which is pretty much impossible at the moment), have a look at the "IPv6 multihoming solutions" page. Are you a BGP expert? Take the test to find out!These questions are somewhat Cisco-centric. We now also have another set of questions and answers for self-study purposes.You are visiting bgpexpert.com over IPv4. Your address is 170.109.232.2. |
No comments:
Post a Comment